Photo : l’équipe de Facebook Engineering au travail.
Récemment une journaliste du journal La Tribune (journal économique et financier Français) m’a contacté pour me poser quelques questions à propos du Hackathon auquel j’avais participé en décembre 2012 en rapport avec le thème de “l’innovation participative”.
Avec mon ami Merlin NIMIER-DAVID nous avons répondu aux questions que cette journaliste nous a posé. Voici le compte-rendu complet de notre échange :
Que cherchiez-vous en participant à cet événement ?
En participant à ce Hackathon, nous cherchions avant tout à nous amuser entre amis développeurs. Nous nous connaissions tous dans notre groupe et nous avions l’habitude de travailler ensemble, autour de projets très sérieux. Le Hackathon était une excellente occasion pour nous de laisser libre court à notre créativité et coder sans avoir de restrictions (pas de cahier des charges, de réunions, de longues phases de test) pour se concentrer sur notre corps de métier : le code que nous écrivons en équipe. C’était une excellente occasion pour se pencher sur de nouveaux défis, découvrir de nouvelles techniques, le tout dans un temps limité !
Nous cherchions également à rencontrer d’autres personnes évoluant dans le même milieu que nous pour voir leurs façons de travailler, leurs idées, leurs habitudes. Il est toujours très intéressant de confronter son travail avec des personnes extérieures et compétentes. C’était par ailleurs l’occasion de créer de nouveaux liens, de se faire de nouveaux amis, et pourquoi pas de chercher du monde à recruter !
Qu’en retirez-vous de plus positif ? Et de négatif ?
Notre plus grande fierté était d’avoir réussi à créer un produit fonctionnel au bout de 28 heures, en équipe. Il était également important pour nous de présenter notre projet aux autres équipes, notre point de vue à propos de celui-ci et d’échanger avec les autres équipes autour de leurs projets.
Les échanges étaient très constructifs durant toute la durée du Hackathon et il était très courant de voir les équipes aller voir ce que faisaient les autres et discuter avec eux durant ces 28 heures. Ceci permettait d’avancer, tous ensemble !
Je pense que c’est cet échange qui est le point le plus positif de l’événement.
Le point le plus négatif était peut-être… De devoir retourner en cours le lendemain ! C’est dur de revenir à “la réalité” après 28 heures de pure concentration, sans sommeil.
Participe-t-on d’abord à ce type d’événement pour « le jeu » ou pour gagner ?
Je pense que les équipes participent avant tout à ce type d’événement pour le jeu, et non dans l’objectif de gagner. Les gens participent pour la bonne ambiance qui règne (locaux mis à disposition, repas et boissons offerts, animations proposées) et pour le défi que représente l’événement (difficulté, créativité, longueur, fatigue).
Bien évidemment chaque équipe fait de son mieux pour réaliser le meilleur projet, mais le véritable but est d’avoir réussi à se surpasser et à réaliser un projet dont l’équipe est fière.
Enfin, personnellement, je pense que pour les développeurs, la reconnaissance de ses “semblables” est très importante. Les collègues savent pertinemment discerner ce qui a été difficile à concevoir et les endroits où des efforts importants ont dû être fournis.
Avez-vous le sentiment de faire partie d’une nouvelle génération de développeurs prêt à prendre des risques, à chercher de son côté sans être payé, seuls, AVANT de se faire repérer par une grande entreprise ou organisation ?
Je ne pense pas que le métier de développeur soit un métier dans lequel on se retrouve par hasard. L’immense majorité des développeurs que je connais ont tout d’abord cherché à bidouiller de leur côté avant de se lancer dans un apprentissage plus classique, scolaire.
C’est pourquoi je pense que la génération actuelle des développeurs est prête à prendre des risques : à monter des projets de son côté, sans entreprise, seul ou entre amis.
L’argent est loin d’être le seul attrait du développeur. Je pense que celui-ci cherche à créer un produit utile à lui-même et à ses utilisateurs, bien construit techniquement et qui aura une certaine notoriété dans la communauté. On ne voit pas souvent les développeurs comme des personnes créatives, et pourtant, je pense fortement le contraire. Écrire du code demande une compréhension de l’utilisation du produit, du rapport qu’aura l’utilisateur avec le produit. Sans parler de la créativité lors de la rédaction du code en lui-même : c’est loin d’être un exercice se faisant automatiquement !
C’est pourquoi de nombreux développeurs cherchent une certaine estime, une reconnaissance de leur travail, au-delà du côté technique pur.
Participez-vous régulièrement à de tels concours ? Comptez-vous le faire à nouveau ?
Malheureusement de tels événements ne sont pas organisés très régulièrement en France pour le moment, encore moins en Normandie. Toutefois je pense que les entreprises commencent à réaliser peu à peu l’intérêt de tels événements pour leurs entreprises. Aux États-Unis par exemple il est très commun que des entreprises organisent des Hackathons internes pour stimuler la créativité de leurs équipes et ainsi privilégier la création de nouveaux produits, qui peuvent être repris en tant que projet à part entière par la suite. Les écoles et universités organisent également de tels événements pour faire parler d’elles et montrer ainsi que leur enseignement est efficace et amène à la création de projets intéressants.
Je pense que ce type d’événement sera bien plus répandu dans quelques années. Ce qui est sûr, c’est que nous y participerons de nouveau, chaque fois que l’occasion se présentera. C’est une expérience très formatrice, un gain d’expérience énorme et de très bons moments. Pourquoi s’en priver ?
Si vous en aviez la possibilité participeriez-vous à un hackathon organisé par Facebook ?
Facebook organise souvent des Hackathons internes et des Hackathons ouverts aux participants extérieurs, dans le but de déceler de futurs recrues. Facebook est une entreprise très attachée à ce concept, cette philosophie du “hacker”. C’est un concept très profondément ancré dans la culture de l’entreprise.
Si nous en avions la possibilité, bien évidemment nous participerions à un hackathon organisé par Facebook. Toutefois, nous ne sommes pas sûrs que nous aurions des chances de finir “bien classé”. Mais je suis certain que l’expérience que nous aurions vécue serait tellement enrichissante que ceci ne nous importerait vraiment pas.




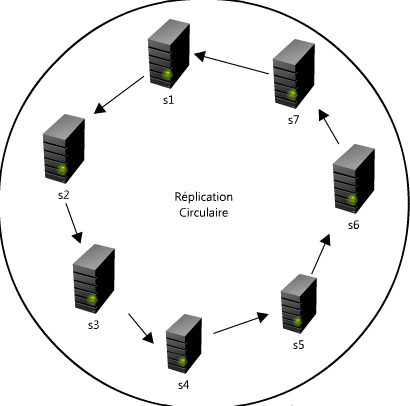
 La réplication de MySQL permet de partager des informations entre des bases de données afin d’être certain que le contenu des différentes bases de données soit exactement le même. La réplication SQL est généralement utilisée pour pouvoir supporter une charge plus importante en répartissant la charge sur plusieurs serveurs, contenant les mêmes bases de données. La réplication peut également être utilisée comme système de sauvegarde ou comme système de fail-over.
La réplication de MySQL permet de partager des informations entre des bases de données afin d’être certain que le contenu des différentes bases de données soit exactement le même. La réplication SQL est généralement utilisée pour pouvoir supporter une charge plus importante en répartissant la charge sur plusieurs serveurs, contenant les mêmes bases de données. La réplication peut également être utilisée comme système de sauvegarde ou comme système de fail-over.