La réplication de bases de données
 La réplication de MySQL permet de partager des informations entre des bases de données afin d’être certain que le contenu des différentes bases de données soit exactement le même. La réplication SQL est généralement utilisée pour pouvoir supporter une charge plus importante en répartissant la charge sur plusieurs serveurs, contenant les mêmes bases de données. La réplication peut également être utilisée comme système de sauvegarde ou comme système de fail-over.
La réplication de MySQL permet de partager des informations entre des bases de données afin d’être certain que le contenu des différentes bases de données soit exactement le même. La réplication SQL est généralement utilisée pour pouvoir supporter une charge plus importante en répartissant la charge sur plusieurs serveurs, contenant les mêmes bases de données. La réplication peut également être utilisée comme système de sauvegarde ou comme système de fail-over.
Le fail-over
Le fail-over s’utilise dans un environnement où il est nécessaire d’avoir une haute disponibilité. Les équipements de fail-over prennent la relève lorsque l’équipement principal rencontre une panne. Ceci permet d’assurer une continuité de fonctionnement des services, alors qu’une panne est survenue.
Mise en place d’une réplication MySQL
Thibault HENRY a écrit un excellent article il y a quelques jours sur la procédure à suivre permettant la mise en place d’une réplication MySQL entre deux serveurs, à l’aide de PHPMyAdmin. C’est très rapide à faire et il suffit de rajouter seulement quelques lignes de configuration sur son serveur. La mise en place est expliquée pour deux serveurs mais peut se généraliser sans problème à n serveurs. Comme je ne pense pas faire mieux que lui, je vous invite à lire son article.
Réplication “classique”
Prenons un modèle à deux serveurs. On nomme S1 le serveur maître et S2 le serveur esclave.
Dans un modèle de réplication classique, les bases de données du serveur S1 sont recopiées, en temps réel sur le serveur S2. Dans un tel modèle on pourrait imaginer une répartition des charges suivantes :
- Les requêtes de lecture se font sur S2.
- Les requêtes d’écriture se font sur S1.
Ou encore :
- S1 est le serveur de production. En temps normal, toutes les requêtes arrivent vers lui.
- S2 est utilisé comme serveur de sauvegarde ou comme serveur de fail-over.
Réplication circulaire
Pour le modèle de la réplication circulaire, voici un schéma qui sera plutôt parlant :
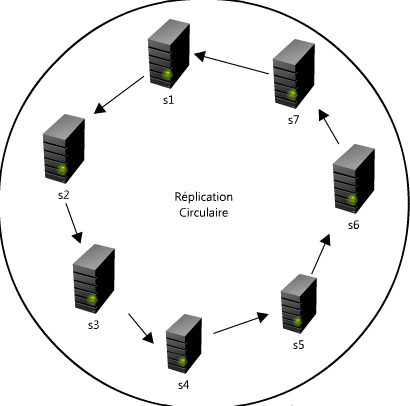
Dans ce modèle chaque serveur est à la fois maître et esclave. Comme disait Maxime VALETTE dans son article de présentation de l’infrastructure SQL de VDM :
Cette configuration a l’avantage de bien fonctionner derrière un load balancer puisque chaque serveur a le droit d’écriture. C’est donc transparent pour le développeur qui n’a qu’à renseigner l’IP du load balancer dans sa connexion à MySQL et travailler comme s’il n’avait qu’un seul serveur.
L’inconvénient est un inconvénient de taille. Comme les requêtes s’exécutent comme dans une ronde, si un serveur plante, toute la ronde est cassée et plus rien ne se réplique. Il faut donc avoir du bon matériel, et au cas où ça arrive quand même, agir très vite.
Éviter l’arrêt de la réplication MySQL
Si vous regardez vos fichiers de log ou directement dans PHPMyAdmin, vous allez remarquer que votre réplication s’arrête relativement régulièrement, pour des erreurs diverses et variées. Les deux erreurs qui reviennent souvent (et qui peuvent être ignorées) sont les suivantes :
- L’erreur 1062. “DUPLICATE ENTRY FOR…” qui se produit sur un INSERT, lorsque vous tentez d’insérer des données déjà existantes ou avec le même ID.
- L’erreur 1053. “Query partially completed on the master (error on master: 1053) and was aborted.” qui est déclenchée lorsque le serveur maître s’arrête, redémarre ou que les tables ont été verrouillées sur le serveur maître (par un exemple pour un dump).
Ces deux erreurs provoquent l’arrêt de la réplication MySQL sur le serveur esclave. Ainsi, tant que vous n’avez pas ignoré ces erreurs (soit automatiquement, soit en ignorant les n prochaines erreurs qui surviendront avec une requête SQL), la réplication ne reprendra pas. Ainsi, vous aurez des bases de données différentes avec des informations de retard sur votre serveur esclave.
Les deux erreurs précédentes ne sont pas d’une grande gravité (un duplicate n’est pas dramatique) mais peuvent nuire au bon fonctionnement de la réplication. La meilleure chose à faire est donc de les ignorer automatiquement, afin qu’elles ne causent pas d’arrêt de la réplication. Il suffit de rajouter dans le fichier /etc/mysql/my.cnf la ligne suivante :
slave-skip-errors=1062,1053
Pensez à redémarrer votre serveur ensuite afin que les modifications soient prises en compte.
Si vous voulez ignorer d’autres erreurs, il suffit de rajouter les codes d’erreurs à la suite !