Facebook Home, c’est quoi ?
Facebook a annoncé le lancement de Facebook Home le 4 avril 2013 après de nombreuses rumeurs autour d’un possible “Facebook Phone”. Facebook Home n’est en réalité qu’une application à télécharger qui modifie votre smartphone en profondeur (écran de verrouillage, menus etc.). L’objectif annoncé de Facebook Home est de placer les personnes au coeur de votre téléphone, et non les applications comme Mark Zuckerberg l’expliquait lors de cette présentation :
“Quand on décide de parler à quelqu’un, ce n’est pas l’application que l’on utilise pour le faire qui est importante. C’est la personne avec qui on souhaite parler.”
Les vidéos de présentation de Facebook Home
Le marketing mené par Facebook autour de son nouveau produit Facebook est assez surprenant. L’entreprise a opté pour une stratégie plaçant le mobile fortement en avant depuis quelques mois et la campagne menée autour de Facebook Home confirme cette volonté. Nouveauté pour le lancement d’un produit Facebook, le lancement a été accompagné de nombreuses vidéos de présentation. Comme pour les précédentes nouveautés on retrouve une page de présentation du produit (www.facebook.com/home) mais je vais m’attarder sur les vidéos associées au lancement de Facebook Home. Je vais vous présenter rapidement les différentes vidéos et m’attarder plus longuement sur la dernière (en tout cas pour le moment) nommée “Facebook Home Dinner”.
La vidéo la plus diffusée
La vidéo la plus mise en avant par Facebook présente le principal avantage annoncé de Facebook Home : il permet d’être connecté encore plus rapidement aux personnes qui nous intéressent. Elle a été diffusée lors de la conférence de présentation du produit et est mise en avant sur la page dédiée. Elle a également été relayée par Mark Zuckerberg sur son compte personnel et par la page Facebook de Facebook sur Facebook (ah ah). On y retrouve tout un tas de personnes, très heureuses et un produit qui leur simplifie la vie. C’est le type de vidéo classique de Facebook : très centrée sur les personnes, Facebook est présent mais toujours pour mieux connecter les personnes.
L’avion
Une personne dans un avion sur le point de décoller jette un rapide coup d’oeil à son téléphone. Il reste connecté à la vie de ses amis en naviguant sur son écran de verrouillage. Ceci est matérialisé par l’irruption dans l’avion de ses amis pratiquant l’activité qu’ils avaient partagé sur Facebook (ce processus sera utilisé dans les autres vidéos).
Le lancement de l’application
Le lancement de l’application s’est fait le 12 avril 2013. Dans cette vidéo, on retrouve Mark Zuckerberg qui vient remercier les équipes d’ingénieurs qui ont travaillé sur Facebook Home. Nouveauté très surprenante pour Facebook, la situation est tournée en dérision encore une fois par les irruptions des amis de l’ingénieur qui jette un coup d’oeil à son téléphone avec Facebook Home. On a pour la première fois un ton comique dans une vidéo de présentation de produit Facebook, chose tout à fait inhabituelle !
Le dîner
Dans cette vidéo, on retrouve une adolescente qui participe à un dîner de famille. Ennuyée par les conversations, elle jette un coup d’oeil à son smartphone pour se distraire et retrouve tout de suite ses amis grâce à Facebook Home (encore une fois, ses amis font irruption dans la pièce).
C’est cette vidéo que je trouve vraiment limite. Je dois avouer que j’avais beaucoup apprécié les autres : très bien réalisées, rigolotes, vraiment jolies. Mais cette vidéo ravive ma peur initiale : a-t-on vraiment besoin d’être toujours sur son smartphone, dans ce cas dans un monde baigné par Facebook ?
L’hyperconnexion
Je trouve que cette dernière vidéo montre le plus la situation dans laquelle sera utilisée Facebook Home : pour se distraire volontairement, s’évader voire même s’effacer de ceux qui nous entourent. Je suis personnellement très sensible à ces problématiques, ayant déjà étudié le phénomène du technostress l’année dernière. Facebook veut pousser ses utilisateurs à une immersion quasi totale de ses utilisateurs dans ses produits (et il n’y a aucun mal à vouloir faire ceci, c’est tout à fait logique). Reste le problème de l’utilisation de ce nouveau produit.
J’avais beaucoup aimé un projet de photographie qui s’intitule “We never look up”. Un photographe rassemble sur un Tumblr des photos de gens utilisant leur smartphone, tablette ou ordinateur dans n’importe quelle situation. Vous pouvez trouver les photos ici : weneverlookup.tumblr.com. Je trouve que ces photos illustrent bien ce problème déjà existant et qui va inévitablement s’aggraver dans les années à venir.
Au final, on peut s’interroger sur la réelle volonté du produit annoncée : mieux connecter les personnes. De toute évidence, lorsque l’on se connecte “mieux” avec une telle application, on se connecte moins bien avec notre environnement. Ces problèmes sont très délicats et j’espère vraiment qu’un jour nous trouverons un moyen de proposer une technologie saine d’utilisation.
Pour aller plus loin
Pour aller plus loin sur le sujet, je vous encourage à lire les nombreux articles qui parlent de Facebook Home sur les blogs spécialisés (TechCrunch, Mashable par exemple).
Sources de Facebook :
- Présentation de Facebook Home : www.facebook.com/home
- La chaîne de Facebook sur YouTube : www.youtube.com/theofficialfacebook
- Facebook Home sur Google Play : play.google.com/store/apps/details?id=com.facebook.home






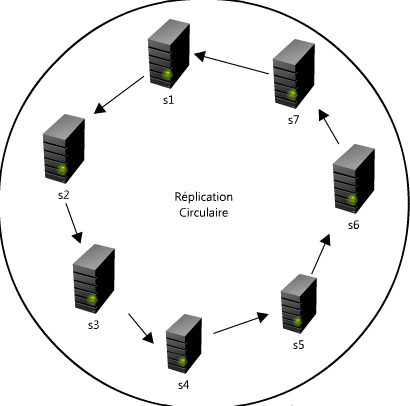
 La réplication de MySQL permet de partager des informations entre des bases de données afin d’être certain que le contenu des différentes bases de données soit exactement le même. La réplication SQL est généralement utilisée pour pouvoir supporter une charge plus importante en répartissant la charge sur plusieurs serveurs, contenant les mêmes bases de données. La réplication peut également être utilisée comme système de sauvegarde ou comme système de fail-over.
La réplication de MySQL permet de partager des informations entre des bases de données afin d’être certain que le contenu des différentes bases de données soit exactement le même. La réplication SQL est généralement utilisée pour pouvoir supporter une charge plus importante en répartissant la charge sur plusieurs serveurs, contenant les mêmes bases de données. La réplication peut également être utilisée comme système de sauvegarde ou comme système de fail-over.