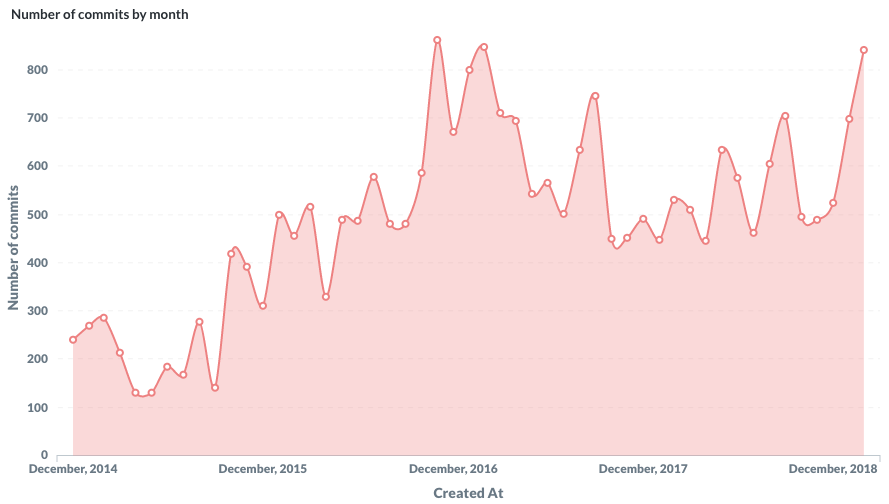
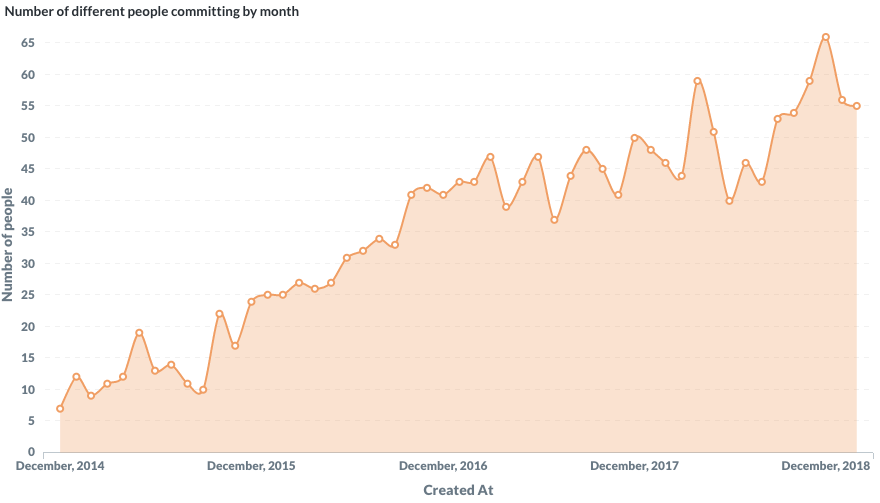
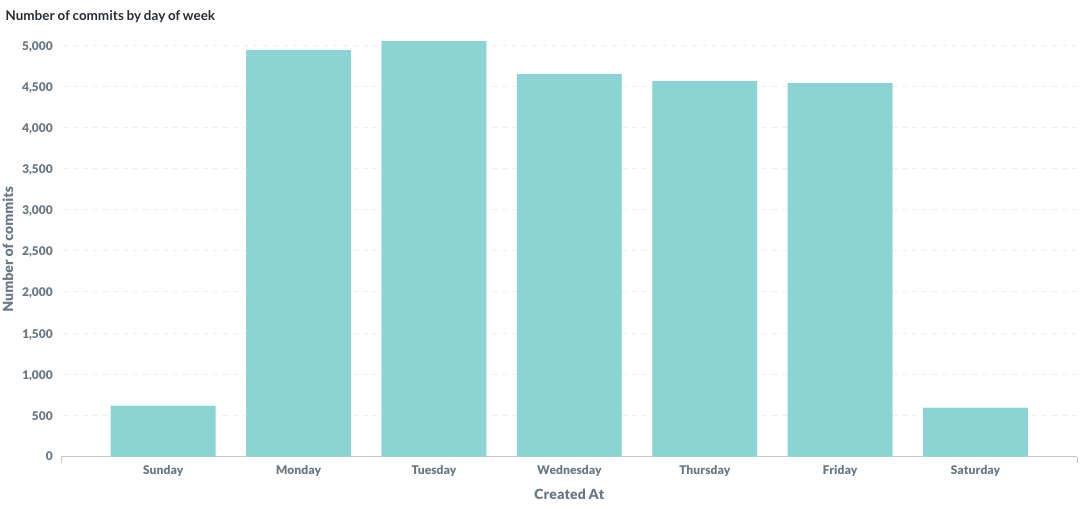
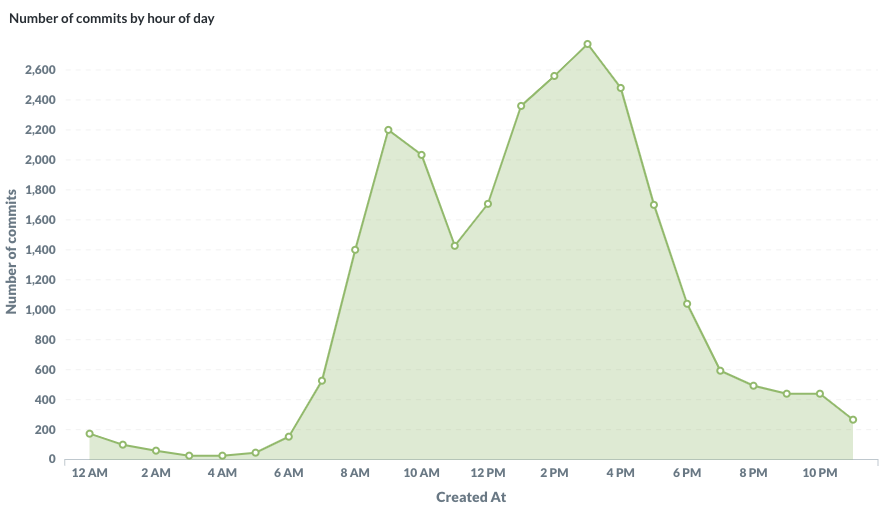
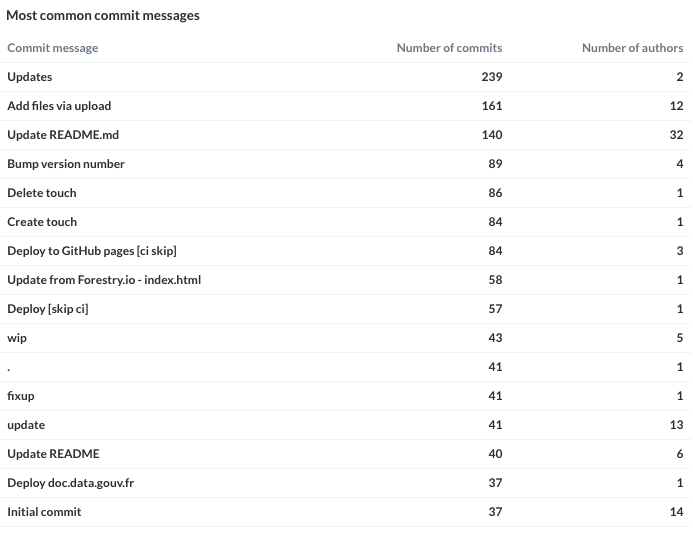
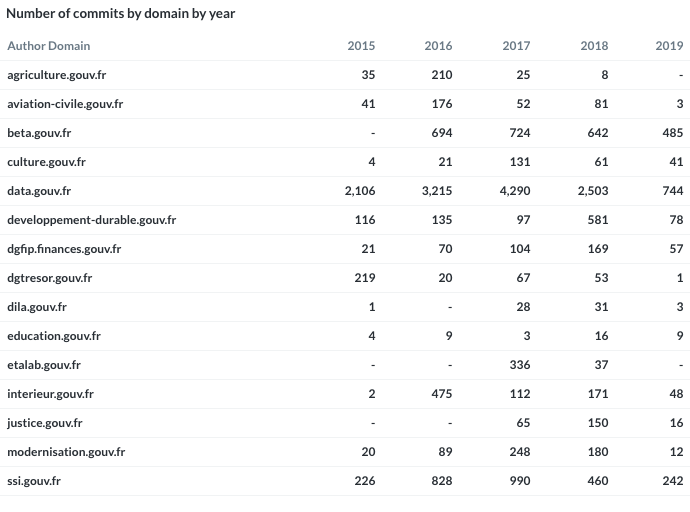
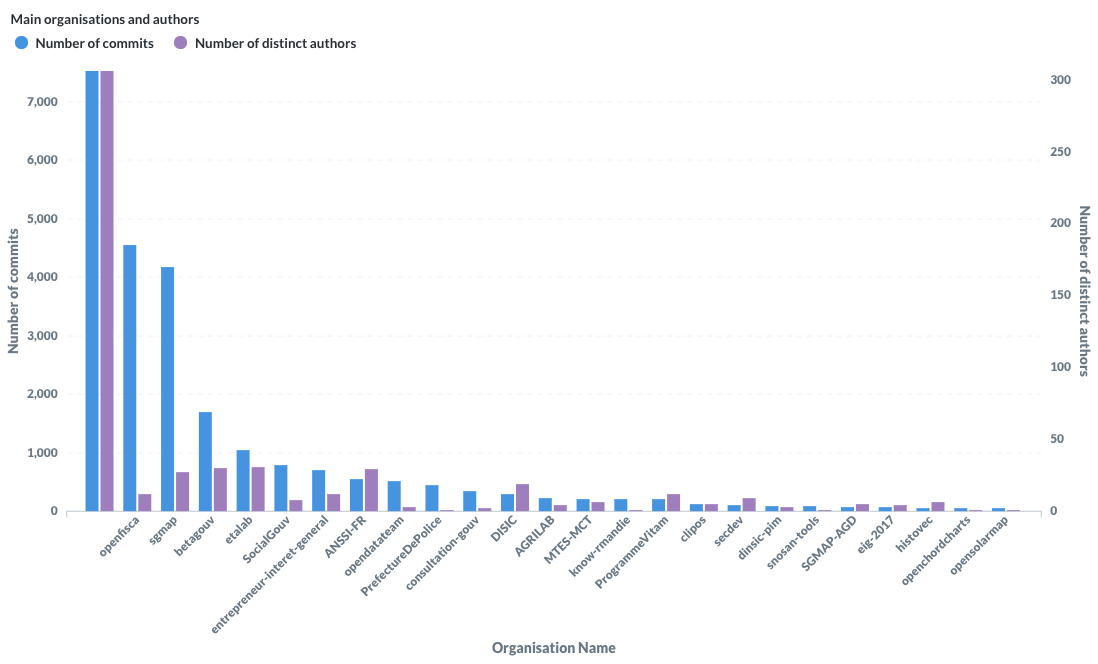
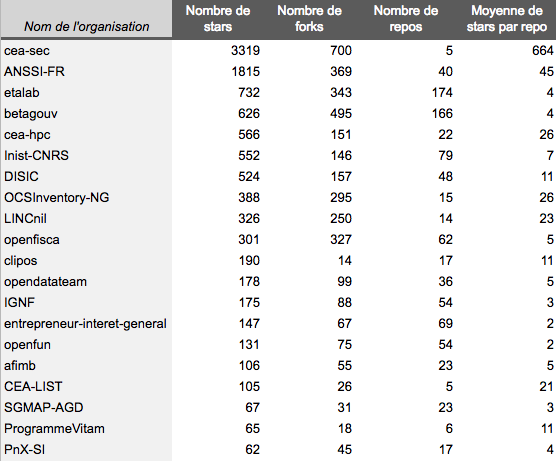
La Société Nationale des Chemins de Fer français (SNCF) est l’entreprise ferroviaire publique française. Le coeur de métier de la SNCF est d’exploiter un réseau ferroviaire et de transporter des passagers. Les chiffres clés sont impressionnants : 15 000 trains commerciaux arpentent le réseau ferré tous les jours, permettant à 4 millions de clients de se déplacer. Souvent décriée pour ses problématiques opérationnelles et sa difficulté à transmettre des informations aux voyageurs, la SNCF s’est notablement améliorée depuis plusieurs années. Cet effort de diffusion, de transparence et d’amélioration continue est visible sur le portail open data de la SNCF data.sncf.com.
Sur ce portail open data, on retrouve des statistiques de régularité au mois et par type de transport (TGV, Intercités, Transilien, TER). Ces données ont un intérêt pour évaluer l’évolution de la qualité de service au fil des années. Je regrette toutefois l’agrégation assez large : au mois / par région / par axe. Les voyageurs sont plus soucieux des régularités aux heures de pointe et durant les jours ouvrés. Espérons que cela évolue vers un découpage par tranches horaires et par jour. Ces jeux de données sont des incontournables étant donné l’activité commerciale de transports de voyageurs de la SNCF.
Toujours sur la régularité mais dans une temporalité différente, la SNCF propose depuis quelques mois un rapport quotidien sur la régularité des différentes lignes et axes sur la journée d’hier. Cette application est nommée Mes trains d’hier. Les faits majeurs sont relatés, expliquant une mauvaise performance. Je regrette la non disponibilité de ces données en open data et l’impossibilité de choisir une date antérieure.

Capture d’écran de l’application Mes trains d’hier
Une thématique souvent absente sur les portails open data mais présente côté SNCF est celle des jeux de données se rapportant aux ressources humaines, aux salariés, mouvements sociaux, congés, accidents du travail. On retrouve ainsi des jeux de données décrivant les nationalités, les genres, les rémunérations, les journées perdues lors de mouvements sociaux. Ce sont des informations que l’on retrouve dans les rapports annuels des grands groupes mais je salue le fait d’en faire des jeux de données à part entière.
Sur la transparence pure, je relève 2 jeux de données très intéressants : les courriers institutionnels entre son équipe dirigeante et les représentants élus de l’État et des collectivités locales et les indicateurs de Responsabilité Sociétale de l’Entreprise pour le groupe SNCF Réseau depuis 2016.
Notons que ces jeux de données ont été diffusés dans un premier temps sous une licence de réutilisation non homologuée. La situation a été rectifiée en juillet 2019, les données sont dorénavant diffusées sous une licence ODbL.
Enfin, je termine cet article avec les jeux de données qui m’amusent le plus :
- La liste des 9500 abréviations utilisées (vraiment ?)
- Les objets trouvés (et restitués !), mis à jour 3 fois par jour, comportant une catégorie Articles d’enfants, de puériculture.
Cet article est un rapide tour d’horizon des jeux de données disponibles en ligne. En août 2019, plus de 215 jeux de données sont publiés sur ce portail. Les thématiques majeures non abordées dans cet article sont l’infrastructure ferroviaire, les services aux voyageurs, la billetique et les gares.